Jacob Devlin, Ming-Wei Chang, Kenton Lee, & Kristina Toutanova (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Abstract
- Bidirectional Encoder Representations from Transformers (트랜스포머를 통한 양방향 인코더 표현)을 소개
- 기존 언어 표현 모델과 다르게, BERT는 모든 레이어의 왼쪽과 오른쪽 맥락을 동시에 고려하는 방식으로 라벨링되지 않은 텍스트로부터 깊은 양방향 표현을 사전 훈련하도록 설계.
- -> 테스크를 위한 구체적인 구조 수정 없이도 하나의 아웃풋 레이어를 추가하는 것 만으로 다양한 태스크를 위한 SOTA 모델을 생성하는 것이 가능.
Introduction
- 언어모델 사전 학습이 많은 NLP 태스크에 있어 효과적임이 증명됨.
- 문장 단계의 태스크 : 문장 간의 연관성을 전체적으로 분석함으로써 예측
- 자연 언어 추론
- parapharsing
- 토큰 단계의 태스크 : 토큰 수준에서 세밀한 아웃풋을 생성
- 개체명 인식
- 질문 답변
- 문장 단계의 태스크 : 문장 간의 연관성을 전체적으로 분석함으로써 예측
- 사전학습된 언어 표현을 후속 태스크에 적용하기 위한 방법은 두 가지가 있음.
- feature-based (ex: ELMo)
- 추가적 특징으로 사전학습된 표현을 포함하는 태스크 구체적인 구조를 사용.
- fine-tuning (ex: OpenAI GPT)
- 최소한의 태스크 구체적인 파라미터를 도입
- 모든 사전학습된 파라미터를 파인튜닝함으로써 후속 태스크에 맞춰 학습.
- feature-based (ex: ELMo)
- 이런 기존의 기술이 특히 fine-tuning 기법에서 사전 학습된 표현의 힘을 제약한다고 주장.
- 주요 제한 사항 : 현대 언어 모델은 단방향이라는 것.
- ex) GPT : 왼쪽에서 오른쪽으로 진행하는 구조를 사용 -> 트랜스포머의 self-attention layer의 이전 토큰만을 접근 가능.
- -> 이러한 제약 사항은 문장 수준에 태스크에 있어 최선은 아니고, 양쪽 방향에서의 맥락을 통합하는 것이 중요한 토큰 단위 태스크에서 fine-tuning 기법을 적용하는 것은 위험할 수 있음.
- 이 paper에서는 BERT를 제안함으로써 파인튜닝 기반 기법을 개선함.
- Masked Language Model을 통해 사전학습을 함으로써 단방향성의 제약을 완화.
- MLM : 인풋의 토큰을 랜덤으로 가린 뒤 문맥만을 통해 가려진 단어를 유추.
- 왼쪽과 오른쪽 문맥을 표현이 융합할 수 있도록 함.
- 다음 문장 예측 태스크를 통해 문장 쌍 표현을 연결해 사전훈련
- Masked Language Model을 통해 사전학습을 함으로써 단방향성의 제약을 완화.
- 기여는 다음과 같음.
- 언어 표현을 위한 양방향 사전 학습의 중요성을 설명.
- MLM을 통해 사전학습된 깊은 양방향 표현을 가능하도록 함.
- 이는 GPT : 사전학습을 위해 단방향 모델을 사용, 그리고 ELMo : 독립적으로 왼쪽-오른쪽, 오른쪽-왼쪽으로 학습된 언어모델을 얕게 연결하기만 함 과 다름.
- 사전학습된 표현이 태스크를 위한 구조를 설계하기 위한 노력을 줄인다는 것을 보임.
- 많은 태스크 구체적인 구조보다 더 잘 작동함으로써 BERT가 넓은 범위의 sentence level, token level의 task에 SOTA를 달성함을 보임.
- 7개의 NLP 태스크에서 SOTA를 보임.
- 언어 표현을 위한 양방향 사전 학습의 중요성을 설명.
Related Work
Unsupervised Feature-based Approaches
- non-neural과 neural에 걸쳐 널리 사용할 수 있는 단어의 표현을 학습하는 연구는 활발히 진행되어 왔음.
- 사전 훈련된 단어 임베딩 : 현대 NLP 시스템의 가장 필수적인 부분.
- 좌에서 우로 단어 예측, 또는 좌우 문백을 통해 올바른 단어와 틀린 단어를 구분하는 목표가 사용됨.
- 이러한 접근이 문장이나 문단 임베딩과 같은 더 덜 세밀한 범위로 일반화됨.
- 다음과 같은 목표들이 문장 표현 훈련을 위해 사용됨.
- 다음 문장 후보 순위를 매김.
- 이전 문장의 표현을 주고 다음 문장 단어를 좌에서 우로 생성
- 오토인코더로 생성된 목표의 노이즈를 제거
- 다음과 같은 목표들이 문장 표현 훈련을 위해 사용됨.
- ELMo와 그 이전 연구들 : 단어 임베딩을 다른 차원에서 일반화함.
- 좌->우, 우->좌 LM을 통해 문맥과 연관된 특징을 추출.
- 각 토큰의 문맥적 표현은 좌->우, 우->좌 표현이 합쳐진 것.
- 존재하는 태스크 구체적인 구조와 문맥적인 단어 임베딩을 통합했을 때, 7개의 major NLP task에서 SOTA를 달성함.
- 그 외 : LSTM을 사용해 좌우 맥락을 모두 고려해 단어 하나를 예측하는 태스크를 통해 문맥적 표현을 학습하는 방법이 제안됨. 특정 단어를 가리고 맞추는 태스크가 문장 새성 모델의 강건함을 개선하는 데 도움이 됨을 보임.
Unsupervised Fine-tuning Approaches
- 라벨링되지 않은 텍스트에서 단어 임베딩 파라미터만을 사전학습한 작업물이 시초.
- 최근은 문맥적 토큰 표현을 생성하는 단어, 문서 인코더가 라벨링되지 않은 문장으로부터 사전학습되고, 하위 태스크를 위해 파인튜닝됨.
- 완전히 처음부터 학습되어야 하는 파라미터의 수가 적다는 장점이 있음.
- 이 장점 덕분에, GPT는 GLUE 벤치마크를 통해 문장 단위 태스크에 있어 SOTA를 달성함.
- 좌-우 언어 모델링, 오토 인코더 목적이 이런 모델을 사전 훈련하는 데 있어 사용됨.
Transfer Learning from Supervised Data
- 대규모 데이터셋을 사용한 지도 학습에서도 효과적인 전이가 가능하다는 것을 확인할 수 있었음.
- 컴퓨터 비전 연구에서도 이미지넷으로 사전 훈련된 모델을 파인튜닝하는 것이 효과적임을 확인함으로써, 큰 사전학습된 모델로부터 전이학습하는 것이 중요함을 확인할 수 있었음.
BERT
모델 구조
- original transformer를 기반으로 한 multi-layer bidirectional Transformer encoder를 사용.
- 두 가지의 모델을 사용. L : layer number, h : hidden size, a : number of self-attention heads
- BERT base : L=12, H=768, A=12, total parameters : 110M (GPT와 비교를 위해 같은 모델 사이즈를 사용)
- BERT large : L=24, H=1024, A=16, total parameters=340M
입/출력 표현
다양한 하위 태스크를 처리할 수 있도록 하기 위해 하나의 토큰 시퀀스에 하나의 문장과 문장 두 개를 모호하지 않게 인풋에 담을 수 있도록 함.
문장이라는 것이 실제 언어적으로 문장이라는 의미보다, 연속된 텍스트의 무작위적인 범위로 생각.
시퀀스 : BERT의 인풋 토큰 시퀀스. 한 문장이나 합쳐진 두 문장이 될 수 있음.
30000개의 단어를 가진 WordPiece 임베딩을 사용.
모든 시퀀스의 시작 : [CLS] 토큰
- 이 토큰과 연관된 마지막 hidden state가 분류 task를 위한 전체 시퀀스의 대표 벡터로 사용됨.
문장 쌍은 시퀀스 하나에 들어가는데, 이는 두 방법으로 구별됨.
- [SEP] 토큰을 통해 문장을 구분.
- 어느 문장에 속하는지 모든 토큰에 임베딩을 추가.
인풋 표현은 해당하는 토큰 임베딩과 어느 문장에 속하는지 임베딩, 그리고 위치 임베딩을 더해 구해짐.
BERT 사전 학습
- 두 가지의 비지도 task를 통해 사전 학습됨.
Masked LM
- 양방향 상황은 단어가 서로를 확인해서, 모델이 다층 맥락에서 타겟 단어를 너무 쉽게 예측할 수 있는 문제점이 존재.
- 이 연구에서는 인풋 토큰의 일부를 가린 뒤, 해당 가려진 토큰을 예측하는 방식으로 훈련.
- 가려진 토큰에 해당하는 퇴종 hidden vector를 소프트맥스에 넣어 단어를 예측함.
- 파인튜닝 시에는 [MASK] 토큰이 사용되지 않음 -> 항상 해당 토큰을 사용하지 않고, 랜덤 토큰이나 원래 그대로의 토큰도 사용.
Next Sentence Prediction
- QA, NLI와 같은 task는 두 문장 간의 관계를 이해하는 것이 필요. -> 이진화된 다음 문장 예측 task를 사전 학습.
- 두 문장을 고르고, 50퍼는 이어지는 문장, 50퍼는 이어지지 않는 문장.
- C 벡터가 NSP에 사용됨.
- 간단하지만, QA와 NLI task에 모두 아주 도움이 됨.
- 기존 연구와 유사하지만, 오로지 문장 임베딩만이 전이되는 기존 연구와는 다른게 BERT는 모든 파라미터가 전이됨.
Pre-training data
- 언어 모델 사전 학습의 기존 문헌을 따라감.
- BooksCorpus, Wikipedia를 사용.
- 긴 연속된 시퀀스를 추출하기 위해 문서 단위 코퍼스를 사용하는 것이 중요.
BERT 파인 튜닝
- transformer의 self-attention : 알맞은 input과 output을 넣는 것만으로도 많은 하위 task를 수행할 수 있도록 함.
- 문장 쌍을 사용하는 응용 : 보통 양방향 cross attention 이전에 문장을 각각 인코딩
- BERT : 두 단계를 합치기 위해 self-attention mechanism 사용 - 연결된 문장 쌍을 self-attention하는 것이 두 문장 간의 양방향 cross attention을 더 효과적으로 포함하기 때문.
- 모든 태스크에 대해 해당하는 Input과 output을 넣고 모든 파라미터를 파인튜닝함.
- input은 다음과 같은 관계를 가짐.
- paraphrasing을 위한 문장 쌍
- 가설-전제 쌍
- 질문-문서 쌍
- 문장 하나
- 토큰 표현 : 토큰 수준 task에 사용됨.
- [CLS] 표현 : 분류에 사용됨.
- fine-tuning : 비교적으로 비용이 덜 듬.
Experiments
GLUE
- General Language Understanding Evaluation
- section 3에서 언급된 것처럼 문장을 정의한 뒤 [CLS] 토큰의 마지막 hidden vector에 해당하는 C를 대표 표현으로 사용.
- 파인튜닝 과정에서 새롭게 도입된 파라미터는 분류 레이어의 weight W뿐
- 일반 분류 손실을 log(softmax(CW ^T))로 계산함.
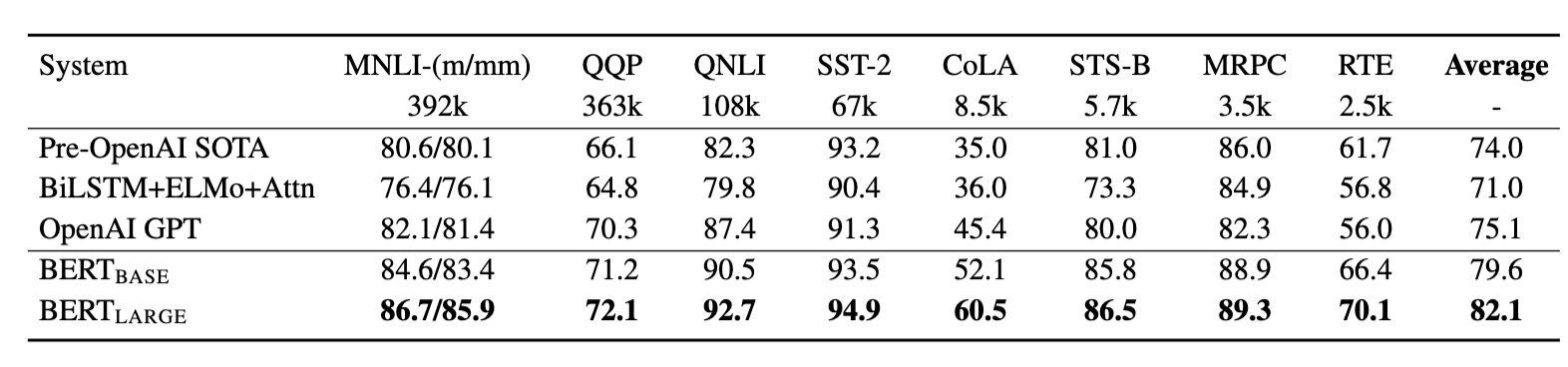
- batch size : 32, 3 epochs
- task에 따라 학습률을 다르게 함.
- 단, BERT large 모델은 작은 데이터셋에서 파인튜닝이 불안정하다는 것을 발견 -> random restart 적용 : 같은 훈련 지점에서 데이터 shuffling과 분류기 층 초기화를 진행.
- 모든 테스크에서 SOTA를 달성
- BERT base와 GPT는 attention masking을 제외하고는 거의 같은 구조를 가짐.
- BERT large가 BERT base보다 높은 성능을 보임, 특히 훈련 데이터가 적은 곳에서 그런 결과를 보임.
SQuAD v1.1
- 질문과 답을 포함하고 있는 위키피디아 문서를 주면, 정답 텍스트 부분을 찾아내는 task
- 파인 튜닝 과정에서 시작 벡터 S와 끝 벡터 E만을 추가.
- 전체 단어에 대해 소프트맥스를 수행해 해당 단어가 답이 될 가능성을 계산.
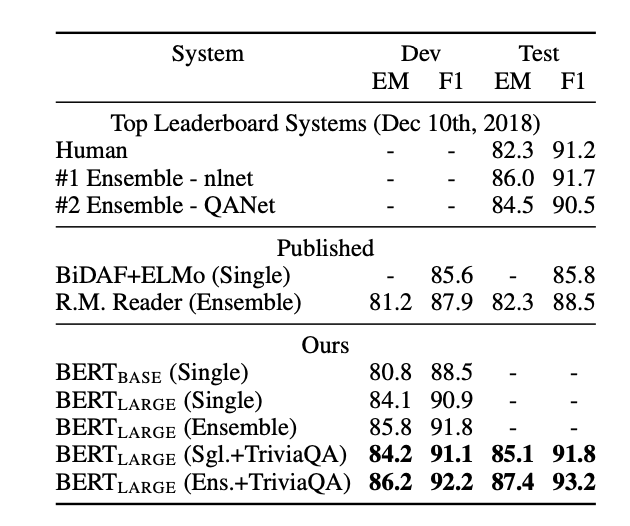
- leaderboard와 비교해, ensemble 모델보다 +1.5 F1, single 모델보다 +1.3 F1을 달성.
- TriviaQA 데이터셋을 사용해 미리 fine-tuning하지 않아도 기존 top ensemble보다 더 잘 작동했음!
SQuAD v2.0
- SQuAD v1.1에서 답이 없는 경우를 추가해, 더 사실성을 높인 task
- 답이 없는 경우를 처리하는 방법? : CLS가 S이고 E이면 no answer!
- 답이 없을 경우 vs 답이 있을 경우를 비교해 정답 span을 도출.
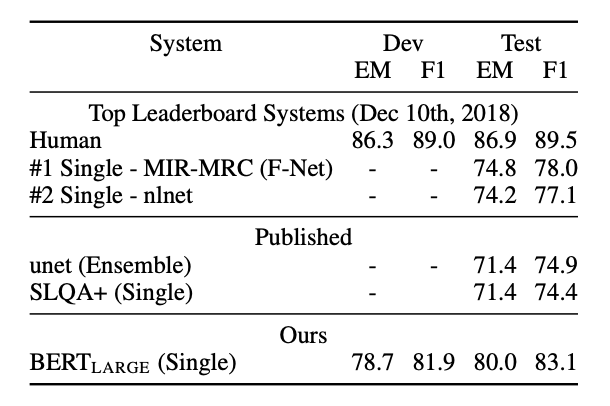
- 기존 best solution에 비해 +5.1 F1의 개선을 보임.
SWAG (The Situations With Adversarial Generations)
- 문장이 주어지면, 4개의 선택지 중 가장 연결이 자연스러운 선택지를 고르는 task.
- 주어진 문장 A와 선택지 B를 concat하여 4개의 input sequence를 생성
- 이후 layer에서 각 선택지에 대한 확률이 얻어짐.
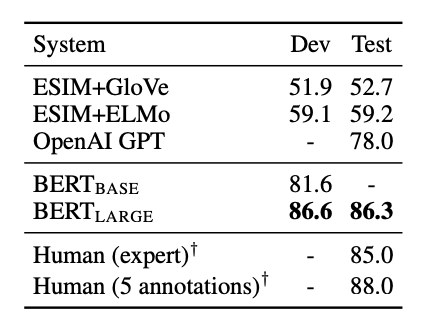
- 기존 저자들의 baseline보다 27.1%, GPT보다 8.3%의 성능 개선을 보임.
Ablation Studies
Effect of Pre-trainig Tasks
- No NSP : no NSP, only MLM
- LTR, No NSP : standard Left-To-Right LM + no NSP
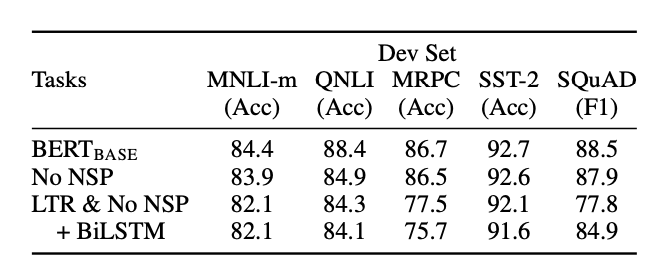
- NSP가 없으면?
- QNLI, MLNI, SQuAD 1.1에서의 성능 저하
- 양방향 학습이 없으면?
- 모두 성능 저하, 특히 MRPC, SQuAD
- -> 두 task가 모델이 잘 학습하는데 있어 매우 중요하다!
Effect of Model Size

- 모델 크기가 커질 수록 잘 작동.
- 특히, data가 매우 작고 task 자체도 training objective와 다른 MRPC에서도 잘 작동했다는 사실이 고무적.
- 모델 크기를 키우는 것이, 만약 충분히 pre-trained 되었다면 아주 작은 task에서도 도움이 된다는 것을 보여주는 첫 사례라고 주장.
Feature-based Approach with BERT
- 다음과 같은 경우에는 feature를 추출하는 것이 도움이 됨.
- task가 구조적으로 Transformer encoder architecture로 표현하기 어려울 때
- 단 한 번의 pre-training으로 얻은 representation을 사용해서 여러 번 적용하고 실험하고 싶을 때. (추가적인 pre-training이 불필요하므로 비용 절약 가능)

- 가장 효과가 좋았던 방법 (Concat Last Four Hidden)이 가장 좋은 결과보다 0.3 F1 차이가 남
- -> BERT가 fine-tuning, feature-based 두 방법에 대해 모두 잘 작동함!
Conclusion
- 언어 모델에 있어서, 비지도로 풍부하게 pre-training -> 전이 학습 : 이 방법이 언어 이해에 있어 매우 중요하다는 것이 실제 결과로 밝혀짐.
- 특히, 이런 학습(단방향)의 결과가 데이터가 작은 task에서도 잘 작동함.
- 우리의 contribution:
- 양방향 architecture 설계, 잘 작동함을 보임.
- pre-trained된 모델 하나를 구조 변경 없이 다양한 NLP task를 풀 수 있도록 함.
Discussion
- 흥미로웠던 점
- 양방향 모델을 설계하기 위한 approach가 신박했음.
- 그냥 양방향을 해버리면 앞뒤 모든 단어를 다 볼 수 있으니까… 가려버리자!
- 또한, 모델 구조 변경 없이 다양한 task를 처리하도록 한 방법이 재미있었음.
- [CLS] token을 exploit해서, 확률을 뱉는다던가 다른 token과의 dot product 결과로 해당 token의 점수를 얻는다던가…
- 양방향 모델을 설계하기 위한 approach가 신박했음.
- 더 생각해볼 점
- 다양한 변종들 (ex: RoBERTa)가 있는 걸로 알고 있는데, 그런 모델들은 어떤 점을 개선했는지?
- 최근에는 classification처럼 discriminative한 task에서도 BERT보다 GPT와 같은 LM을 많이 쓰는데, 더 구조가 해당 task에 optimal한 BERT를 덜 사용하는 이유는?