저는 이번 학기 캡스톤디자인을 통해 멀티모달 환경에서의 연합학습이라는 주제로 연구를 진행하고 있습니다. 연구에 도움이 될 만한 다른 연구를 찾아보는 중, fine-tuning을 위해서 엄청난 연산이 필요한 대규모 pre-trained 모델을 제한된 리소스로 학습을 진행해야 하는 연합학습 환경에 최적화시켜 적용하는 FedCLIP 연구를 발견하게 되었습니다. 이미 학습된 좋은 모델을 사용하지 못하는 환경에 맞추어 모델을 최적화한다는 발상이 흥미로웠고, 그 코드도 모두 공개가 되어있어 직접 시연을 해볼 수 있는 상황이었기 때문에 따라서 이 주제로 글을 작성하게 되었습니다.
CLIP이란?
FedCLIP에 대해 설명하기 위해서는 먼저 CLIP에 대해 간단히 알고 넘어갈 필요가 있습니다.
CLIP은 2021년 OpenAI에서 공개한 이미지-텍스트 멀티모달 모델로, 논문은 다음 링크에 공개되어 있습니다.
https://arxiv.org/abs/2103.00020
CLIP은 contrastive learning을 통해 학습을 진행합니다. (이름도 그래서 Contrastive Language-Image Pre-training의 줄임말)
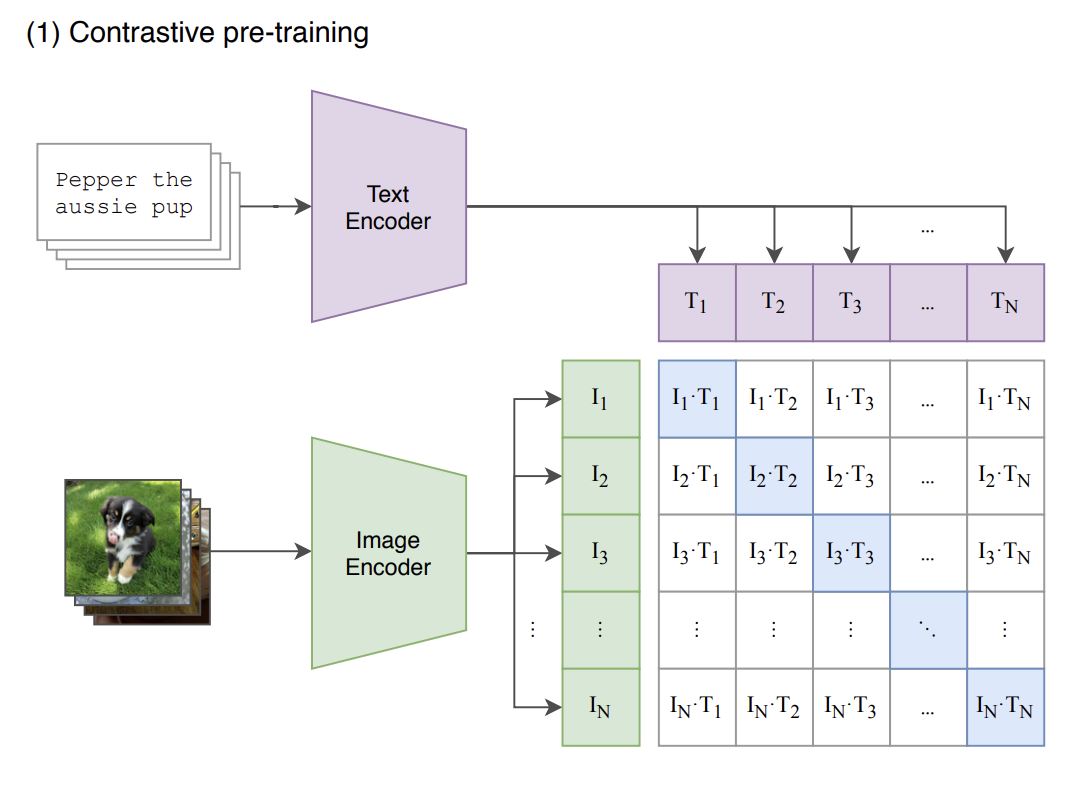 논문의 이미지를 가지고 왔습니다.
각각 설정한 text encoder, image encoder를 통해 텍스트와 이미지를 넘기면(논문에서는 이미지에는 resnet과 vision transformer, 텍스트에는 transformer을 사용했다고 합니다) 텍스트와 이미지를 각각 벡터로 변환해줍니다. 그리고 두 벡터 쌍의 dot product를 구하면 그림과 같이 다양한 pair가 나오게 될 텐데, 여기서 색칠이 되어있는 각 텍스트와 이미지에 대응되는 pair에 가중치를 주어 학습을 시키는 것이 CLIP의 핵심입니다.
논문의 이미지를 가지고 왔습니다.
각각 설정한 text encoder, image encoder를 통해 텍스트와 이미지를 넘기면(논문에서는 이미지에는 resnet과 vision transformer, 텍스트에는 transformer을 사용했다고 합니다) 텍스트와 이미지를 각각 벡터로 변환해줍니다. 그리고 두 벡터 쌍의 dot product를 구하면 그림과 같이 다양한 pair가 나오게 될 텐데, 여기서 색칠이 되어있는 각 텍스트와 이미지에 대응되는 pair에 가중치를 주어 학습을 시키는 것이 CLIP의 핵심입니다.
 마찬가지로 논문에서 가지고 온 수도코드입니다.
보면 두 벡터의 닷 프로덕트를 구한 뒤 대응되는 pair의 cosine similarity는 크게, 그 외는 작게 만드는 것이 학습의 핵심입니다.
마찬가지로 논문에서 가지고 온 수도코드입니다.
보면 두 벡터의 닷 프로덕트를 구한 뒤 대응되는 pair의 cosine similarity는 크게, 그 외는 작게 만드는 것이 학습의 핵심입니다.
FedCLIP이란
현재 CLIP은 text-image 분야에서 SOTA 모델로 알려져 있는데요, 이 모델을 연합학습 환경에도 적용할 수 있다면 정말 좋지 않을까요?
하지만 CLIP은 어마어마하게 거대한 규모의 데이터를 통해 학습한 모델이기 때문에, 그 파라미터 수도 정말 많고, 따라서 리소스가 제한되는 연합학습 환경에서는 도입하기가 어렵다는 문제점이 있습니다.
따라서 FedCLIP은 CLIP을 연합학습 환경에 맞추어 미리 학습된 인코더는 그대로 사용하고, 대신 각 기기별로 어댑터를 학습해, 이를 통합하여 하나의 완성된 어댑터를 만드는 방식으로 이 문제를 해결하였습니다.
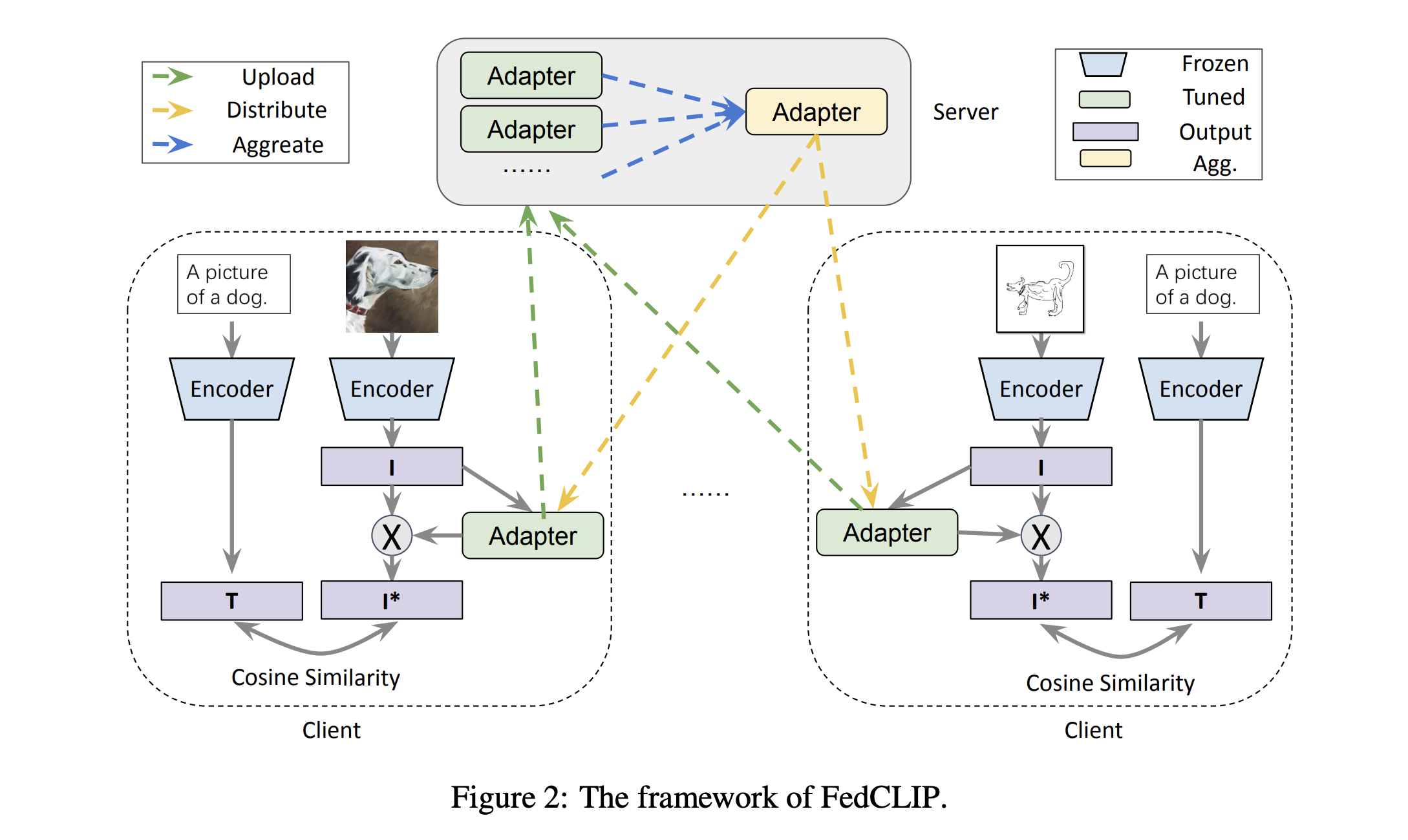 FedCLIP의 학습은 다음 과정으로 진행됩니다.
FedCLIP의 학습은 다음 과정으로 진행됩니다.
- 인코더를 통과시켜 T와 I를 얻는다.
- I를 어댑터에 통과시켜 I* 를 얻는다. 그리고 CLIP과 같이 같은 쌍의 cosine similarity는 가깝게, 반대는 멀게 어댑터를 학습시킨다.
- 얻은 어댑터를 서버로 전송한다.
- 어댑터의 평균을 구한 뒤 해당 어댑터를 각 기기로 전송한다.
- 이 과정을 반복한다.
이 때 사용하는 어댑터는 어텐션을 기반으로 한 AttAI라는 어댑터로, 하나의 완전연결층, Tahn 활성화 함수, 하나의 완전 연결층, 그리고 소프트맥스로 이루어져 있습니다. 미리 학습된 인코더를 사용하여 이미 충분히 학습된 검증된 자원을 사용하면서, 인코더를 기기마다 학습시킨 뒤 통합하고 분배하여 튜닝한다는 점이 흥미롭습니다. 어댑터라는 개념의 도입을 통해 기기에서도 CLIP을 통한 학습을 가능하게 했다니, 정말 재미있지 않나요?
참고로 여기서는 image에 adapter를 달았지만, text에 다는 것도 가능하다고 언급되어 있습니다. 해당 방식으로는 어떤 결과가 나올지도 궁금해지는 부분입니다.
코드 실행 준비
FedCLIP의 코드는 모두 깃헙을 통해 공개되어 있습니다. https://github.com/microsoft/PersonalizedFL/tree/main/fedclip 먼저, 파이썬 버전을 3.8.5로 맞춰줍니다. 기존에 설치되어 있는 파이썬을 삭제하고 싶지 않은 경우에는, virtualenv를 통해 가상환경을 설정하는 것이 가능합니다.
그 다음, 요구사항을 맞춰줍니다. 다음과 같은 요구사항을 맞춰줄 필요가 있습니다.
$ pip install ftfy regex tqdm
$ pip install git+https://github.com/openai/CLIP.git
$ pip install -r requirements.txt
$ pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/cu111/torch_stable.html
이 때, +cu111은 cuda가 설치되어 있는 윈도우즈에서만 설치가 가능합니다.
위 요구사항을 모두 설치한 뒤, 데이터셋을 다운로드 받습니다. 사용한 데이터셋은 PACS로, 물체 인식에 사용되는 데이터셋입니다. 4개의 sub-dataset과 7개의 class를 포함하고 있습니다.
wget https://wjdcloud.blob.core.windows.net/dataset/PACS.zip
unzip PACS.zip
리눅스 환경에서는 다음 명령어를 통해 설치하고 압축 해제가 가능합니다. 다만 윈도우즈에는 wget 명령어가 존재하지 않기 때문에, 해당 링크로 바로 접속하면 다운로드가 가능합니다.
이후 아래의 네 명령어를 각각 수행하는 것을 통해 직접 FedCLIP을 실행해볼 수 있습니다!
python methods/fed_at_clip.py --dataset pacs --mode FedAtImg --test_envs 0 --iters 200 --wk_iters 1 --lr 5e-05
python methods/fed_at_clip.py --dataset pacs --mode FedAtImg --test_envs 1 --iters 200 --wk_iters 1 --lr 5e-05
python methods/fed_at_clip.py --dataset pacs --mode FedAtImg --test_envs 2 --iters 200 --wk_iters 1 --lr 5e-05
python methods/fed_at_clip.py --dataset pacs --mode FedAtImg --test_envs 3 --iters 200 --wk_iters 1 --lr 5e-05
다음은 윈도우즈 환경에서 직접 FedCLIP을 실행하는 글을 가져오겠습니다!