Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training.
BOAZ에서 발제를 진행한 논문이다.
옆 링크에서 당시 발제 자료를 확인할 수 있다. 링크
Abstract
- 데이터는 많은데, 특성 태스크에 맞춰져서 라벨링된 데이터는 부족. -> 성능 저하로 이어짐.
- 이 논문에서는, generative pre-training을 통해 라벨링되지 않은 수많은 corpus를 활용하는 방법을 제안. + 태스크에 맞춰 discriminative fine-tuning
- fine-tuning 과정에서는, 모델의 구조는 거의 변경하지 않으면서 input을 task에 맞추어 적절하게 변형함.
Introduction
- 라벨링되지 않은 언어 데이터가 많은데, 만약 라벨링된 데이터를 사용한다면 많은 도움이 됨.
- 거기에, unsupervised된 상황에서 학습이 진행되면 성능 향상에 더 도움이 됨. ex) word embeddings
- But, word level 이상으로 라벨링되어 있지 않은 텍스트에서 정보를 끌어내는 것은 쉽지 않음.
- 어떤 목적함수를 설정해야 할 지가 불분명.
- 목적 task에 어떻게 해야 가장 효과적으로 지식을 전달할 수 있는지 명확하지 않음.
- 이 논문에서는?
- 비지도 pre-training + 지도 fine-tuning -> 준지도학습을 진행
- unlabeled data로 초기 파라미터 학습 -> 특정 task에 맞춰진 labeled data로 튜닝.
- 약간의 수정만으로도 다양한 task를 수행 가능한 공통 표현을 생성하는 것이 목표.
- 비지도 pre-training + 지도 fine-tuning -> 준지도학습을 진행
Related Work
Semi-supervised learning for NLP
- 단어 또는 구 수준의 통계를 계산하는데 unlabeled 데이터를 사용하는 것에서 시작.
- unlabeled 코퍼스를 통해 훈련하여 word embedding을 얻어 사용하는 것이 유용함이 밝혀짐.
- but, 단어 수준의 정보만을 얻을 수 있음.
- -> 구, 또는 문장 수준의 임베딩을 얻는 연구가 진행됨. 본 연구도 높은 수준의 언어 맥락을 구하는 것을 목표로 함.
Unsupervised pre-training
- 지도 학습 목표를 바꾸는 대신 좋은 초기화 시점을 찾기 위해 시작됨.
- 심층 신경망의 일반화에서 효과적이라는 사실이 밝혀졌고, 여러 태스크에 적용됨.
- 위는 주로 CV 분야이고, NLP에서도 language modeling 목표로 사전학습 후 파인튜닝을 진행한 연구가 있지만, LSTM의 한계로 성능이 좋지는 않았음.
- -> 이 연구에서는 Transformer 구조를 사용해 그러한 제약을 극복.
- 사전훈련된 language model이나 기계 번역 모델의 hidden representation을 보조 feature로 사용하여 target task에 대해 supervised learning을 진행한 사례도 존재.
- but, 이렇게 하면 각각의 태스크에 대해 너무 많은 새 파라미터가 요구됨.
- -> 이 연구에서는 전이 과정에서 모델 구조의 최소한의 변경을 요구하도록 함.
Auxiliary training objectives
- 보조 목적을 NLP 태스크에 있어 사용한 사례가 많이 존재. -> POS tagging, chunking, …
- 이 실험에서도 보조 목적을 사용함.
Framework
1. Unsupervised pre-training
큰 corpus를 모델에 학습시키는 과정.
다음과 같은 objective function을 사용 $$L_1(u) = \sum_ilogP(u_i|u_{i-k}, …,u_{i-1};\theta)$$
k라는 context window를 가질 때, $i-k$ 번째부터 바로 전 토큰를 보고 $i$번째 토큰을 맞출 확률을 계산. -> 여기에 log를 씌우고 전부 합함.
해당 확률이 높아지도록 SGD를 사용해 훈련.
모델로 Transformer decoder를 여러 층으로 사용.
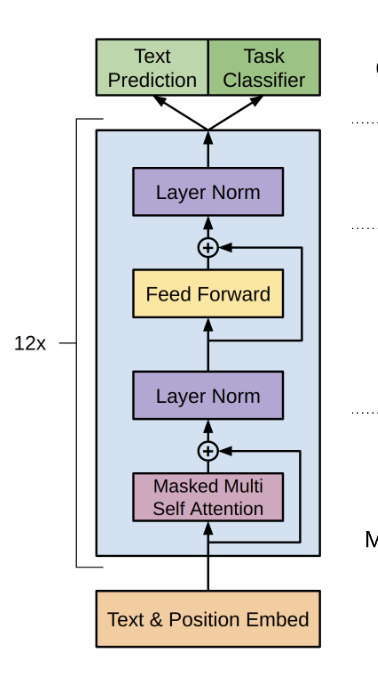
- multi-headed self-attention -> position-wise feedforward layers.
2. Supervised fine-tuning
- 1처럼 모델을 훈련시킨 후, task에 맞춰 파라미터를 수정함.
- 모든 토큰을 넣은 뒤 정답 label y가 나올 확률을 transformer block을 모두 통과했을 때 최종 state $h_l^m$과 임의 하이퍼파라미터 $W_y$의 곱의 softmax로 구함.
- 이 값을 최대화하는 것이 목표.
$$L_2(C) = \sum_{(x, y)}log P(y|x^1,…,x^m)$$
- 여기에, 언어 모델링 (위의 $L_1$ 함수)을 보조 목표로 추가하는 것이
- 지도 모델의 일반화 성능 향상
- 수렴 속도 향상
- 에 도움이 된다는 사실을 찾아냄.
$$L_3(C) = L_2(C) + \lambda * L_1(C)$$
3. Task-specific input transformations
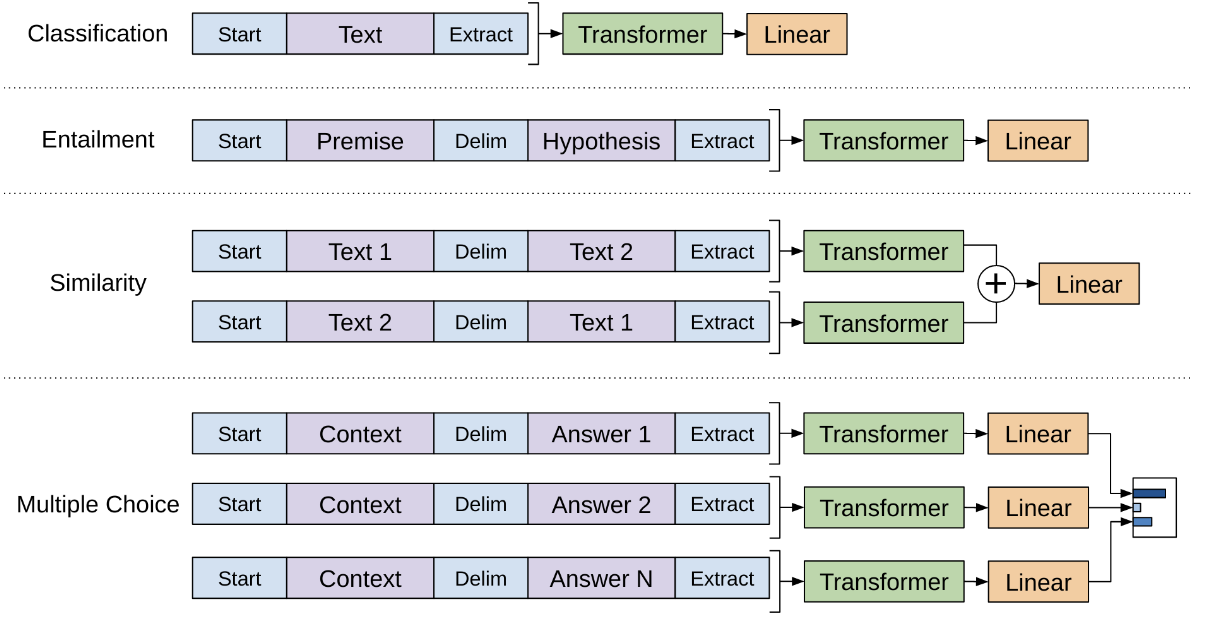
- classification과 같은 task는 위의 방식으로 바로 fine-tuning이 가능하지만, 몇몇 다른 task는 정해진 input 형식 (문장 쌍, 세 문장) 이를 변형하는 것이 필요함.
- 모델이 이러한 input을 받아들일 수 있도록 ordered sequence로 변환. -> task에 따라 불필요하게 구조를 바꾸는 것을 막아줌.
Similarity
- 두 문장에 대해 일정한 순서가 정해져 있지 않으므로, 가능한 두 순서 모두로 input을 만들어 representation을 뽑고, 서로 더함.
Question Answering and Commonsense Reasoning
- 질문과 답에 대해 각각 input을 만든 다음 모델을 통과시키고, 가능한 답에 대해 또 softmax를 통해 확률분포를 구함.
Experiments
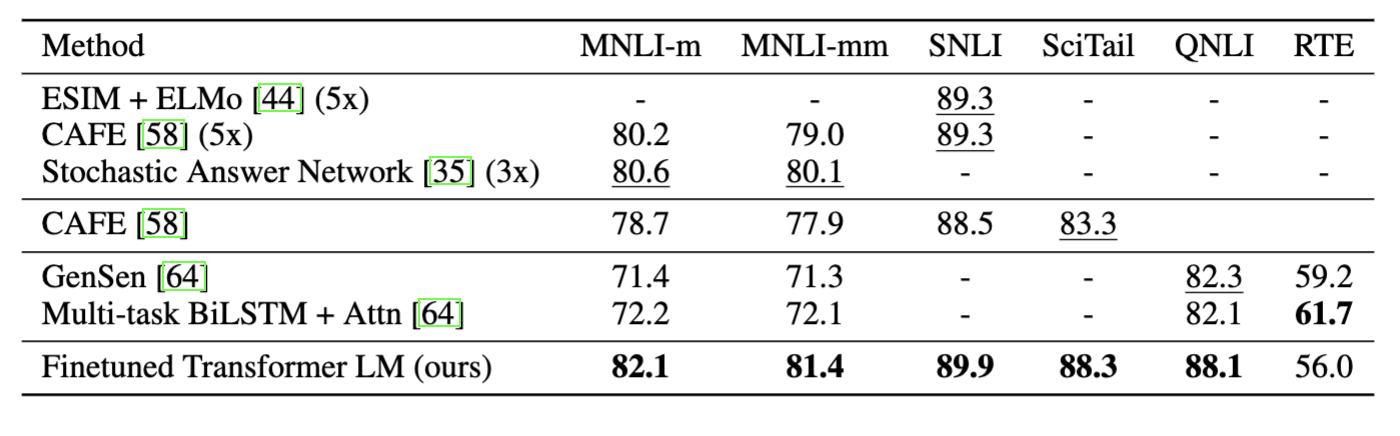
- NLI에서 RTE를 제외하고 SOTA
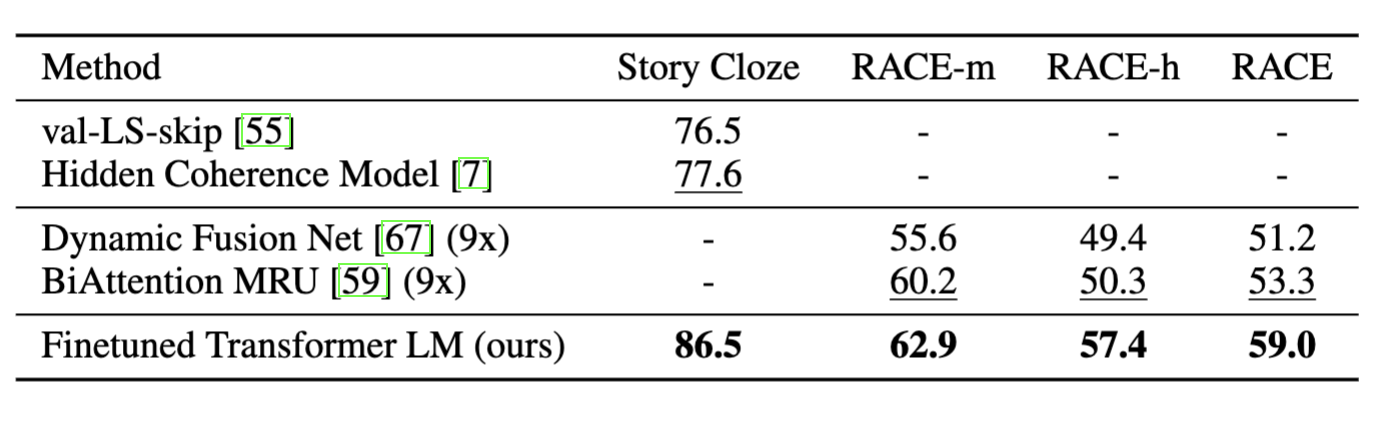
- QA & CR : 모두 SOTA
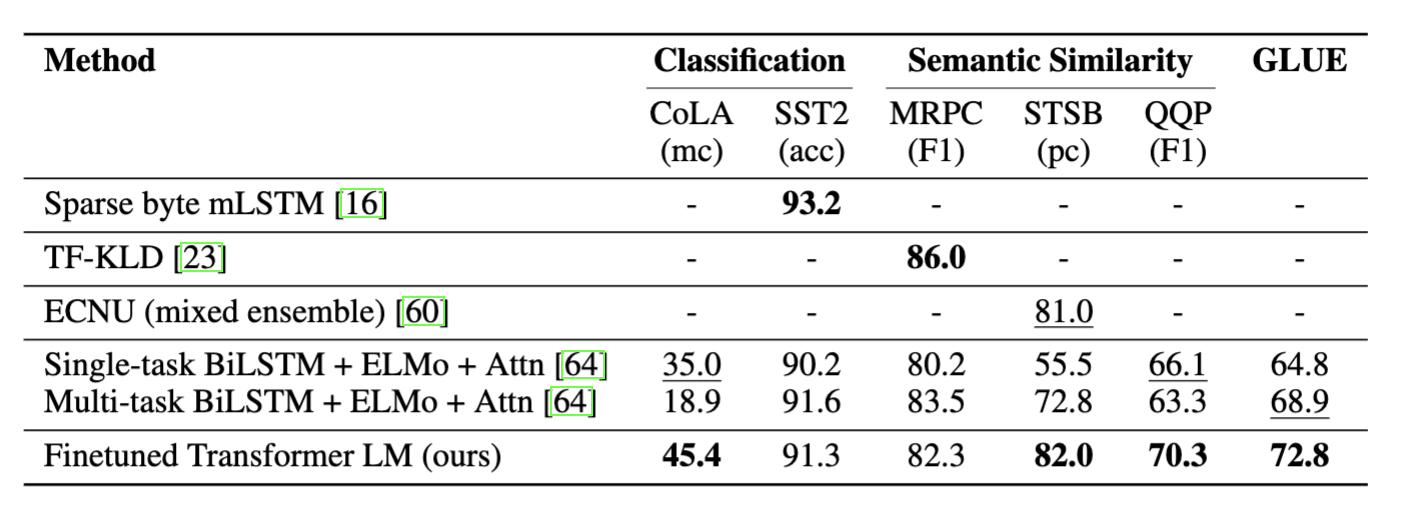
- Classification, Semantici Similarity : SST2, MRPC를 제외한 모든 데이터셋에서 SOTA
Analysis
Impact of number of layers transferred
- layer의 수가 증가함에 따라 정확도도 증가 -> pre-training이 도움이 됨.
Zero-shot Behaviors
- Pre-training 횟수가 증가할 수록 점점 더 좋은 성능을 보임.
- But, LSTM은 결과가 변동성이 심함
- 이를 통해
- Pre-training이 언어 능력을 습득하는데 도움을 줌.
- Transformer 구조가 지식 전이에 더욱 적합한 구조임.
Ablation Studies
- 보조 목적 유무 : dataset이 크면 있는 것이 유리.
- LSTM과의 비교 : Transformer보다 낮은 성능을 보임.
- Pre-training 유무 : 있을 때가 더 좋은 성능을 보임.
Conclusion
- Transformer 구조와 긴 맥락의 data + generative pre-training & discriminative fine-tuning으로 엄청난 성능 향상을 보임.
Discussion
- 이후 논문들에서는 모델을 키우고 + 데이터셋을 늘리는 방향으로 발전시켜 실제로도 엄청난 성능 향상을 이뤄냄. -> 결국 deep learning 모델은 scale이 커지는 방향으로 발전시킬 수 밖에 없는것인가… 라는 생각이 듬.
- 따라서 이러한 추세를 거스를 수는 없는 것 같고, 점점 더 무거워지는 모델에 대한 optimization이 더더욱 필요하겠다…라는 생각을 했음.
- 보조 목적을 사용했는데, BERT 같은 경우 이러한 보조 목적을 변형하여 더 좋은 성능을 얻은 변종들이 있는 것처럼 GPT도 그런 모델들이 있는지?
- 다른 objective가 아닌 Language Model을 선택한 이유가 있는지? -> 이건 기본적인 언어 능력을 얻기 위해서는 말을 생성하는 task를 배우는 것이 다른 task에 비해서 가장 직관적으로 말을 할 수 있게 되는 것이기 때문에, 가장 효과적이지 않았을까 생각이 듬…